


تمام نیازهای برنامه AI/ML خود را با راه حلهای بهینه شده سرور GPU سوپرمیکرو برطرف کنید.
خلاصه اجرایی
گسترش سریع برنامههای هوش مصنوعی (AI) و یادگیری ماشین (ML) در تمام ابعاد تجارت و زندگی روزمره باعث ایجاد انفجاری در Big Data میشود. این پیشرفت هزینهای به همراه دارد، با این وجود نیاز به آموزش مداوم و مجدد و تنظیم بیش از حد پارامتر زمان، بیشتر از آنچه که اکنون عادی به نظر میرسد، دارد. علاوه بر این، AI/ML برای آموزش مدل به قدرت پردازش زیادی نیاز است.
الگوریتمهای یادگیری ماشین با محاسبات فشرده هنگام استفاده از سختافزار بدون ویژگیهای شتاب، زمان طولانیتری را طی میکنند که به عملکرد ضعیف برنامه و کاهش بازگشت سرمایه میانجامد. با این تقاضای فزاینده برای برنامههای کاربردی AI/ML، مراکز داده سازمانها در حین کوتاه کردن زمان آموزش، بودجه و فضا و منابع IT را نیز منطبق میکنند.
با توجه به گسترش نامحدود مجموعه دادهها و همچنین برنامههای محاسباتی و پرمخاطره، مدیران مراکز داده باید سریعا از قدرت پردازش لازم و تطبیق پلتفرمهای AI/ML برای تأمین نیازهای تجاری خود مطمئن شوند. با انتخاب مناسب فروشندگان، راه حلهای برنامه همراه با سختافزار به کاربران کمک میکنند تا روندها و الگوها را شناسایی کنند، که این امر باعث خروجی و زمان آموزش بهتر میشود، و بنابراین به چرخه مثبتی از پیشرفت میانجامد. این مقاله یکی از راه حلهای AI/ML از شرکت سوپرمیکرو را شرح میدهد.
راه حل AI/ML سوپرمیکرو
توصیف کلی
همچنان که هوش مصنوعی و راه حلهای یادگیری ماشین در دسترستر و پختهتر میشوند، سازمانهای جهانی به ارزشی که این راه حلها میتوانند برای حل چالشهای پیشرفته تجاری ارائه دهند، پی خواهند برد.
راه حل AI/ML سوپرمیکرو از یکی از بهترین پلتفرمهای سختافزاری و Canonical Distribution of Kubernetes (CDK) آماده شده شرکتی برخوردار است و دارای قابلیتهای ذخیرهسازی تعریف شده توسط نرمافزار Ceph است. این راه حل از طریق معماری مرجع خود شبکه، محاسبه و ذخیرهسازی را ادغام میکند. اجرای آغازین شامل پیشنهاد یک rack با قابلیت مقیاس گذاری تا چند rack در صورت لزوم است.
معماری مرجع AI/ML
معماری مرجع، آمادهی استفاده از راه حل AI/ML ،end to end است که شامل پشته AI SW ،orchestration و مخازن است. طراحی مرجع بهینه متناسب با آموزش یادگیری ماشین و برنامههای استنباطی است. معماری سطح بالا شامل نرمافزار، سوئیچهای شبکه، کنترل، محاسبه، ذخیرهسازی و خدمات پشتیبانی است.
طرح مرجع نشان داده شده در شکل 1 شامل دو سوئیچ داده، دو سوئیچ مدیریتی، سه گره زیرساختی که به عنوان گرههای پایه برای MAAS/JUJU عمل میکنند و شش گره ابر است. این طرح در پلتفرم Kubernetes ساخته شده است و بستههای سخت شده Canonical را برای مخازن Kubernetes و Ceph فراهم میکند. Kubeflow مجموعه ابزار یادگیری ماشین برای Kubernetes فراهم میکند.
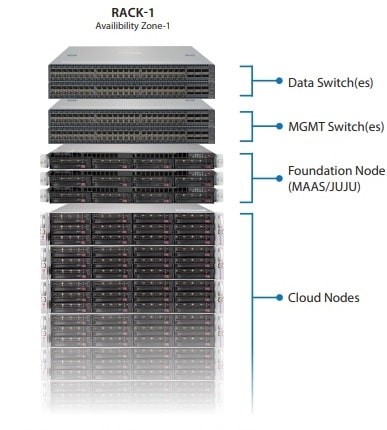
شکل 1. معماری مرجع AI /ML سوپرمیکرو
پیکربندی راه حل
- حداکثر 216 هسته محاسباتی
- حداکثر 3072 گیگابایت حافظه سیستم
- حداکثر 36 ترابایت فضای ذخیرهسازی
- حداکثر 40 گیگابایت اترنت شبکه داده
- ارتفاع 19U
- حافظه پنهان با عملکرد بالا با استفاده از حافظه فلش NVMe
نکات اصلی شامل موارد زیر است: معماری مرجع مجاز با اجزای معتبر و آزمایش شده، از یک تا چندین rack، سرورهای صرفه جویی green Resource برای ابر که صدها دلار به ازای هر سرور صرفه جویی میکند، عملکرد پیشرو در صنعت، خدمات مشاوره اختیاری و پشتیبانی و راه حل بهینه شده برای شرکای مجاز Intel AI.
این راه حل در خانوادههای سرور Ultra و BigTwin سوپرمیکرو ساخته شده و معتبر است و همچنین از سوئیچهای اترنت سوپرمیکرو مانند SSE-G3648B (مدیریت/سوئیچ ترافیک IPMI)، SSE-X3648S (سوئیچ شبکه داده 10 گیگابایت اترنت)، SSE-F3548S (سوئیچ شبکه داده 25 گیگابایت اترنت) و SSE-C3632S (سوئیچ شبکه داده 40 گیگابایت اترنت) استفاده میکند. در واقع برای عملکردهای بهینه شده و ارائه بالاترین سطوح قابلیت اطمینان، کیفیت و مقیاس پذیری طراحی شده است.
چگونه راه حل سوپر میکرو استفاده میشود؟
راه حل سوپرمیکرو توسط مدیران فناوری اطلاعات، دانشمندان داده و توسعه دهندگان استفاده میشود. مراحل روند بکارگیری در ادامه بیان شده است.
بکارگیری برای مدیر IT
مرحله 1. با سیستمهای مدیریت شده IPMI، به شبکه برای مدیریت داده وصل شوید.
مرحله 2. برای افزودن منابع سختافزاری مورد نیاز، YAML را بهروز کنید و خوشه Kubernetes را نصب کنید.
مرحله 3. برای مقیاس گذاری، دستور“Juju add-unit Kubernetes-worker” یا برای از بین بردن، دستور “juju remove-machine <Node-id>” را صادر کنید.
IPMI برای اتصال به شبکه جهت مدیریت داده استفاده میشود. پس از اتصال، مراحل 2 و 3 امکان افزودن منابع سختافزاری و استفاده از دستورات JUJU را برای مقیاس گذاری و بعداً برای غیرفعال کردن تجهیزات خارج از سرویس فراهم میکند.
بکارگیری برای دانشمندان داده و توسعه دهندگان
روند بکارگیری راه حل برای دانشمندان داده و توسعه دهندگان به طور خلاصه در ادامه بیان شده است:
1. شبکههای معروف (مانند Resnet ،Inception و غیره) را کپی کنید یا از git hub بگیرید.
2. برای ایجاد حجم مداوم یک YAML ایجاد کنید.
3. برای آموزش یا استنباط هدف یک YAML ایجاد کنید.
4. منابع مورد نیاز که برای اجرای گرههای خاص به طور مداوم مطالبه میشوند را اضافه کنید.
جریان راه حل سوپرمیکرو چگونه کار میکند؟
Kubeflow یک پروژه منبع باز است که به ارائه منابع یادگیری ماشین (ML) با کاربرد آسان در بالای خوشه Kubernetes اختصاص دارد. با استفاده از Canonical MAAS و Juju، راه اندازی محیط Kubernetes/ Kubeflow نسبتا ساده و کنترل کننده Juju، بکارگیری خوشه Kubernetes را بر اساس زیرساخت پشتیبانی شده بر روی یک گره و خوشه چند گرهه آسان میکند. با Kubeflow نصب TensorFlow آسان میشود و با افزودن سیستمهای سوپرمیکرو حاوی شتاب دهندههای مناسب (Intel MKL)، میتواند عملکرد شتاب گرفتهای را برای مشاغل ارائه شده ML فراهم کند. سرانجام، Prometheus برای نظارت و هشدار رویداد قابل استفاده است.
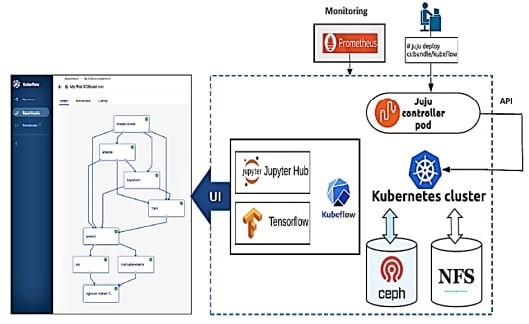
شکل 2. شرح تصویری جریان AI/ML سوپرمیکرو
جزئیات سیستم
معماری راه حل
پیکربندیهای AI/ML سوپرمیکرو بر اساس منابع محاسباتی با چگالی بالا و فضای ذخیرهسازی توسط نرمافزار برای Cloud و معماری مقیاس بندی، بهینه شدهاند.
سیستمهای راه حل سوپرمیکرو دارای جدیدترین پردازندههای مقیاس پذیر نسل دوم Intel Xeon همراه با مدلها و بستههای ML بهینه شده اینتل هستند. این سیستمها همچنین از سیستمعامل Ubuntu ،Kubernetes ،Kubeflow، ذخیرهسازی Ceph و سوئیچهای شبکه سوپرمیکرو استفاده میکنند تا اطمینان یابند که زیرساخت مقیاس بندی شده، عملکرد بهتر، خروجی و زمان سریعتر آموزش را فراهم میکنند.
معماری شبکه
همانطور که دادهها به ترتیب ترابایت و پتابایت به صورت تصاعدی رشد میکنند، زیرساخت شبکه به راه حل ذخیرهسازی مقیاسپذیر قابل اعتمادی نیاز دارد. Ceph سیستم ذخیرهسازی ترجیحی برای دستیابی به زیرساخت شبکه پایدار و قوی است. خوشه ذخیرهساز مقیاس پذیر و مقاوم به خطا، با مدیریت خروجی دادهها و الزامات تراکنش کاربر، به زیرساختی با عملکرد بالا تبدیل میشود.
علاوه بر این، راه حل AI/ML متشکل از سوئیچهای مدیریت دوگانه (IPMI وKubernetes)، سوییچهای داده دوگانه، سه گره زیرساختی و شش گره ابری است. سوئیچ مدیریتی، اتصال 1 گیگابایت بر ثانیه را پشتیبانی میکند و در هر سه گزینه شبکه که 10، 25 و 40 گیگابایت بر ثانیه است، مشترک میباشد. بعلاوه، سوئیچ داده از 10، 25 و 40 گیگابایت بر ثانیه نیز پشتیبانی میکند. سوئیچهای داده 10 و 40 گیگابایت اترنت به سیستمعامل Cumulus نیاز دارند، در حالی که سوئیچ داده 25 گیگابایت اترنت به سیستمعامل سوپرمیکرو SMIS (Society for Management Information Systems) نیاز دارد.
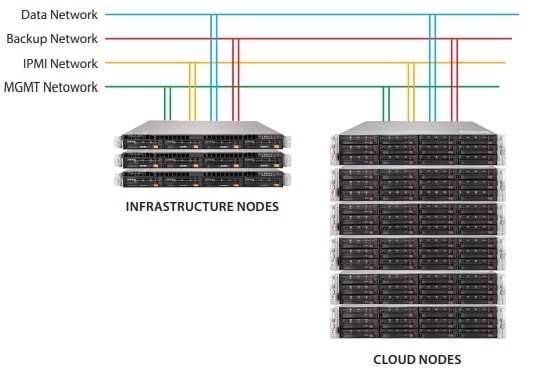
شکل 3. نمودار معماری شبکه
پیکربندی
اجزای AI/ML شامل سه گره زیرساختی Ultra سوپرمیکرو (SYS-6019U- TN4RT)، شش گره ابری Ultra (SYS-6029U-TR4T) و دوازده دیسک داده گره ابری (درایوهای U.2 NVMe) است. پیکربندی همچنین شامل مجوزهای Ubuntu Advantage Advanced و Ubuntu Kubernetes Discoverer و خدمات اختیاری شامل اعتبار سنجی طراحی مرکز داده و خدمات راه اندازی، خدمات یکپارچهسازی rack و پشتیبانی در محل سوپرمیکرو میباشد.
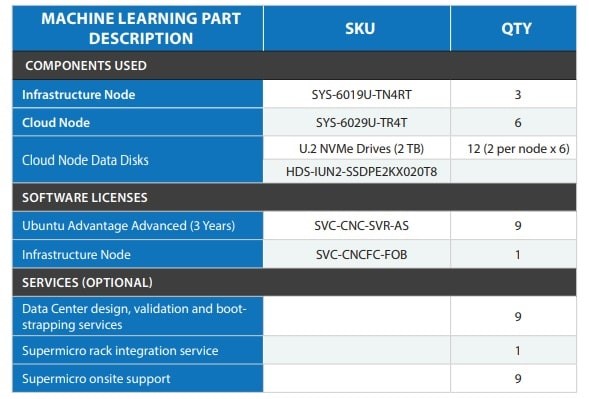
شکل 4. توصیف پیکربندی بخش ML ،SKU، مقدار
نتایج معیار
پردازندههای مقیاسپذیر نسل دوم Intel Xeon تقریبا 25٪ نتایج عملکرد بالاتری نسبت به سیستمهای نسل قبلی هم در آموزش و هم در استنباط با تست معیار CNN نشان دادند.
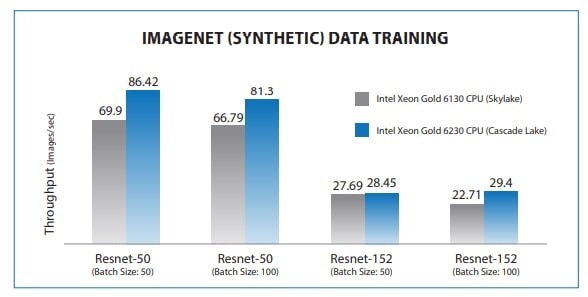
شکل 5. مقایسه معیار آموزش Skylake و Cascade lake، با استفاده از SYS-6029U-TR4 با 2 پردازنده Intel Xeon Gold 6130
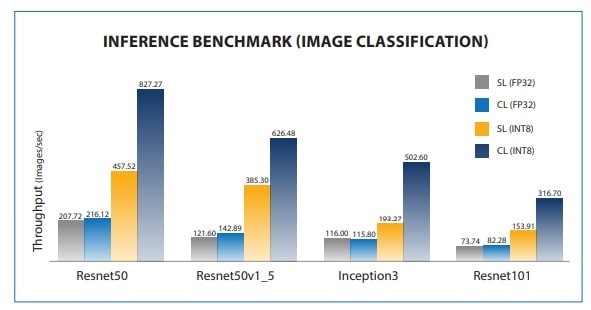
شکل 6. مقایسه معیار استنباط Skylake و Cascade lake، با استفاده از SYS-6029U-TR4 با 2 پردازنده Intel Xeon Gold 6130
BigTwin با پردازنده مقیاسپذیر Intel Xeon پلاتینیوم 8260L، خروجی بهتری در آموزش و استنباط نشان داد.
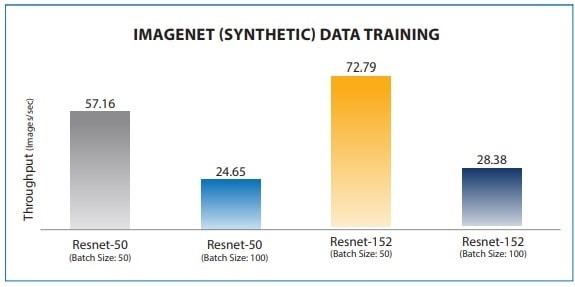
شکل 7. معیارهای آموزش با استفاده از BigTwin (SYS-2029BT-HNC0R) با 2 پردازنده Intel Xeon Platinum 8260L
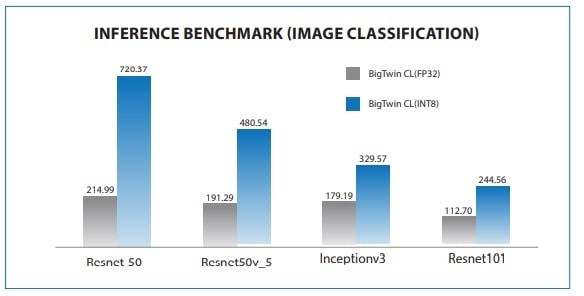
شکل 8. معیارهای استنباط با استفاده از BigTwin (SYS-2029BT-HNC0R) با 2 پردازنده Intel Xeon Platinum 8260L
پشتیبانی و خدمات
Canonical و سوپرمیکرو دریک مشارکت، پشتیبانی شرکتی برای توزیع Canonical ازKubernetes را فراهم میکنند. این مشارکت خدمات کشف و طراحی سرویس را ارائه میدهد، زیرساختها را به اندازه و مشخصات مورد نیاز تقسیم و به مشتریان در دستیابی به مجموعه دانش و تخصص جهانی کمک میکند.
نتیجه گیری
راه حل آماده end to end ،AI/ML سوپرمیکرو به راحتی قابل استفاده است و جزئیات پیادهسازی سطح پایین را مدیریت میکند، بنابراین توسعه دهندگان، دانشمندان داده و مدیران فناوری اطلاعات میتوانند بهرهوری بیشتری داشته باشند. این راه حل مجاز، به عنوان بستر مناسبی برای آموزش یادگیری ماشین و نیازهای استنباطی عمل میکند. همچنین خروجی رقابتی فراهم کرده است و با سرعت بخشیدن به محاسبات و حجم کار برنامههای پرمخاطره AI/ML، زمان آموزش/استنباط را کاهش میدهد.
سوپرمیکرو با سختافزار بهینه شده سرور/ذخیره سازی/شبکه و قدرت محاسبات با کارایی بالا، همراه با تطبیق زیرساخت AI/ML، میتواند روندها و الگوها را از Big data شناسایی کند و برای حجم کار یادگیری ماشین اقدامات مناسب را انجام دهد تا خروجی و زمان آموزش بهتری حاصل کند که منجر به نتایج موفقیت آمیز تجاری شود.














.w_188,h_155,r_k.png)








