


replication چیست؟(رپلیکیشن چیست؟) یک نوع فرآیند تکثیر داده ها و انتقال آنها به سرور و یا مکان دیگری است. معنی replicate، تکثیر، تکرار کردن، یا تقلید کردن است. این واژه در موارد مختلف و در زمینههای مختلف مورد استفاده قرار میگیرد. درواقع مفهوم Data Replication به این معنی است که از داده ها کپی های متعددی در مکان های مختلف داشته باشیم که اگر اطلاعات یک سازمان به هر دلیلی دچار مشکل شد، از اطلاعات مهم و ضروری خود یک نسخه پشتیبان داشته باشیم. البته امروزه تکنیک های Data Replication بسیار متنوع شده و انواع روش های تکثیر داده ها وجود دارد.
تکثیر داده ها چیست؟
تکثیر دادهها در واقع همان Data replication است که با هدف پشتیبان گیری از داده ها، بهبود دسترسی و کم شدن خطا نیز انجام می شود.
replication (تکثیر داده ها) به دو صورت همزمان و غیر همزمان انجام میشود.
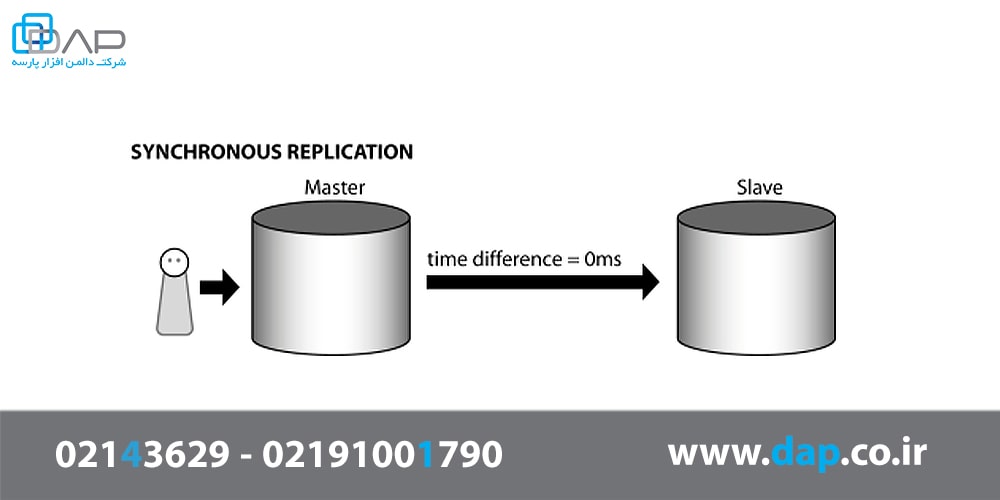
رپلیکیشن همزمان یا Synchronous Replication
در رپلیکیشن همزمان، کپی کردن داده های چندین مخزن اطلاعاتی بلافاصله (در یک واحد زمانی) انجام میشود. رپلیکیشن همزمان روشی هزینه بر است و پهنای باند بسیار زیادی لازم دارد اما در مواقع ضروری که نیاز به بازیابی اطلاعات است، بسیار قابل اعتماد می باشد.
رپلیکیشن همزمان به ظرفیت پردازشی بالایی نیاز دارد چون در غیر این صورت باعث کاهش عملکرد و کند شدن سیستم اصلی میشود. این روش بیشتر برای سازمان هایی مناسب است که زمان بازیابی اطلاعات باید کم باشد.
رپلیکیشن غیرهمزمان یا Asynchronous Replication
در رپلیکیشن غیرهمزمان، برخلاف رپلیکیشن همزمان، کپی اطلاعات در زمان های مشخص شده انجام میشود. در این روش اطلاعات پس از نوشتن کامل، بلافاصله تکثیر نشده و اطلاعات در یک دوره زمانی معین کپی می شود.
رپلیکیشن غیرهمزمان پهنای باند کمی استفاده میکند و برای فواصل دور مناسب است. این روش بیشتر
برای بیزینس هایی کاربرد دارد که هنگام بازیابی اطلاعات، زمان زیاد برایشان مهم نیست و میخواهند همانندسازی را به صورت بهصرفهتری انجام دهند.
در این روش به دلیل غیر همزمان بودن، ممکن است پشتیبان گیری به صورت صد در صد انجام نشود، بنابراین برای اطلاعات مهم و حساس کاربردی ندارد.

تفاوت replication همزمان و ناهمزمان
در رپلیکیشن همزمان انتقال داده بلافاصله انجام میشود در صورتیکه در ناهمزمان با تاخیر یا در زمان های مشخص انجام می گیرد.
عملکرد سیستم و سرعت پاسخ دهی در رپلیکیشن همزمان کاهش یافته در صورتی که در ناهمزمان افزایش می یابد.
رپلیکیشن همزمان برای موقعیتهایی که یکپارچگی دادهها بسیار مهم است، مناسب می باشد در صورتی که رپلیکیشن ناهمزمان برای موقعیتهایی که سرعت پاسخدهی مهم است، کارایی دارد.
انواع replication (تکثیر داده ها)

انواع replication را می توان به صورت زیر دسته بندی کرد:
- همانند سازی بر اساس Host-based
در سرورها از برنامههای خاص استفاده شده و اطلاعات سرور اصلی به سرور همانند سازی منتقل میشود. مزیت این روش این است که دقیقاً یک کپی از سرور گرفته میشود و در سرور مشابه قرار میگیرد.
- همانند سازی بر اساس Hypervisor-based
این روش به صورت خاص برای استفاده از ماشینهای مجازی است. به این معنی که کل ماشین مجازی در یک سرور میزبان دیگر کپی میشود. این روش باعث میشود که در زمان بروز فاجعه به سرعت اطلاعات از روی سرور اصلی خوانده شده و مشکلی سیستم را تهدید نکند.
- همانند سازی بر اساس Array-based
دادهها به صورت خودکار تکثیر پیدا کرده و روی هارد دیسکهای مختلف قرار میگیرند. در این روش اطلاعات به صورت همزمان روی چندین هارد دیسک با چیدمانهای مختلف تکرار میشود و اطلاعات میتواند در محلهای مختلفی کپی شوند.
- همانند سازی بر اساس Network-based
در این روش شما برای تکثیر دادهها به یک سوئیچ تحت شبکه نیاز دارید. وظیفه این سوئیچ انتقال اطلاعات بین یک هارد دیسک و سرور و کاربران است. در این روش تمامی اطلاعات روی یک سرور و هارد دیسک قرار میگیرد و از پراکندگی اطلاعات جلوگیری میشود.
مزایای تکثیر داده ها (Data replication)
همانطور که قبلا گفته شد تکثیر دادهها (Data replication) یعنی تولید و ذخیره چندین نسخه از دادهها در مکانهای مختلف. این فرآیند مزایای زیادی دارد که در زیر به برخی از این مزایا اشاره میکنم:
۱. بالا بردن قابلیت اطمینان: با تکثیر دادهها در مکانهای مختلف، احتمال از دست دادن داده به دلیل خرابی سختافزاری یا مشکلات شبکه کاهش مییابد. در صورت خرابی یک سرور یا مکان ذخیرهسازی، دادهها همچنان در دیگر مکانها قابل دسترسی هستند و سیستم قابل اعتمادتر میشود.
۲. افزایش عملکرد و کارایی: با توزیع دادهها در مکانهای مختلف، بار مربوط به دسترسی به دادهها بین سرورها تقسیم میشود. این کار باعث بهبود زمان پاسخ و عملکرد کلی سیستم میشود. همچنین، با توزیع بار، امکان افزایش مقیاس پذیری سیستم نیز فراهم میشود.
۳. حفاظت در برابر از دست رفتن دادهها: در صورتی که یک مکان ذخیرهسازی دچار مشکل شود یا دادهها در آن از بین بروند، نسخههای دیگر دادهها در مکانهای دیگر هنوز موجود و در دسترس هستند. این امر موجب حفاظت از دادهها در برابر از دست رفتن یا حذف غیرمنظم میشود.
۴. پشتیبانگیری و بازیابی آسان: با رپلیکیشن، نسخههای پشتیبان از دادهها در دسترس هستند. این به مدیران سیستم امکان میدهد که در صورت نیاز به بازیابی دادهها در صورت از دست رفتن یا خرابی، از نسخههای پشتیبان استفاده کنند و سیستم را به حالت قبلی بازگردانند.
۵. مقابله با بار زیاد: با توزیع دادهها و تکثیر آنها، سامانه قادر به مقابله با بار زیاد ترافیک و تقاضا است. در صورتی که تعداد کاربران و ترافیک بالا رود، سرورها و مکانهای ذخیرهسازی اضافی میتوانند بار را تقسیم کنند و بهبود کارایی سیستم را فراهم کنند.
به طور کلی، تکثیر دادهها امکانات بی نظیر افزایش قابلیت اطمینان، عملکرد بهتر، حفاظت در برابر از دست رفتن دادهها، پشتیبانگیری و بازیابی آسان، و مقابله با بار زیاد را در سیستمهای ذخیرهسازی ایجاد میکند. با توجه به نیازها و محدودیتهای سیستم، روشهای مختلفی برای تکثیر دادهها، مانند تکثیر داده مستقیم (eager data replication) و تکثیر داده تاخیری (lazy data replication)، مورد استفاده قرار میگیرند.
نویسنده: محبوبه سردشتیان














.w_188,h_155,r_k.png)








