



معماری Cache Accelerated Sequential Layout (CASL) از شرکت Hewlett Packard Enterprise نقاط قوت ذخیره ساز HPE Nimble را که شامل عملکرد بالا، بازده ظرفیت، محافظت از دادههای یکپارچه و سادهسازی مدیریت را فراهم میکند.
CASL یک LFS (سیستم فایل با ساختار ورود به سیستم) است که بهترین ویژگیهای رسانههای چرخان (ورودی/خروجی ترتیبی) و فلش (ورودی/خروجی تصادفی) را با هم ترکیب میکند.
این مقاله لایههای معماری CASL را بیان میکند، اهداف مختلف هر لایه را توضیح و نحوه تعامل آنها با یکدیگر را نشان و همچنین مکانیسمهای محافظت از دادهها و یکپارچگی دادهها، همراه با مزایای معماری را توضیح میدهد.
تاریخچه معماری CASL
هنگامی که CASL در سال 2008 طراحی شد، حافظه فلش مورد توجه قرار گرفت. در آن زمان، بنیانگذاران (Umesh Maheshwari و Varun Mehta) در ابتدا نخستین سیستم SSD 2U 24x را طراحی کردند تا با پیگیری درخواستهای NFS کلاینت/سرور، به عنوان یک شتابدهنده حافظه پنهان فلش عمل کند. در شکل زیر مزایای شتاب دهنده ذخیره ساز بیان شده است:
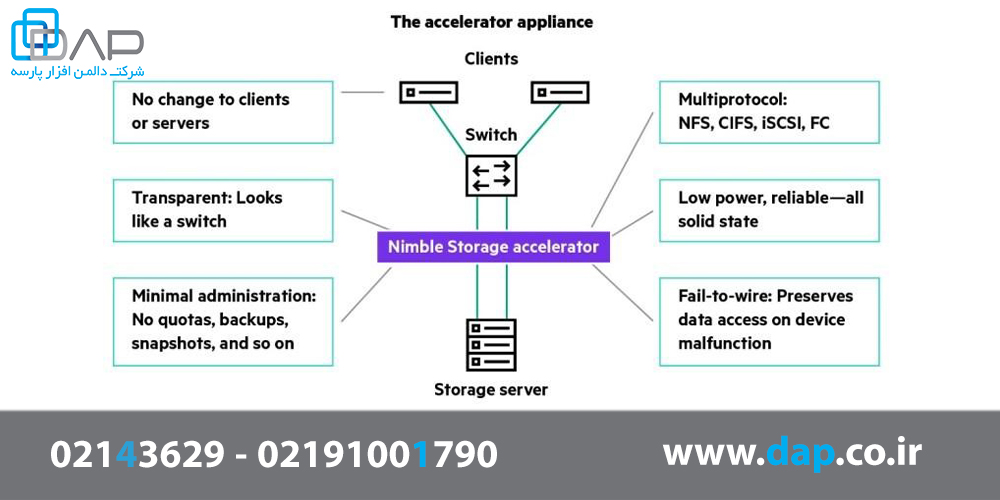
شکل 1 - شتاب دهنده ذخیره ساز
سپس در سال ۲۰۰۹ آنها تصمیم گرفتند تا از شتابدهنده چشمپوشی کرده و با گسترش استفاده از معماری موجود و سیستم فایل که قبلاً توسعه داده بودند، یک سیستم ذخیرهسازی مستقل و نیز یک آرایۀ فلش ترکیبی ایجاد کنند.
معماری HPE Nimble Storage CASL از استوریج های all-flash تا هیبریدی و دوباره به all-flash تحول صنعتی بیسابقهای را به وجود آورده است که انعطافپذیری و انطباق آن را با نیازهای در حال تغییر بازار به نمایش میگذارد.
مرکز طراحی معماری CASL
اصول طراحی که زیربنای معماری CASL است، این پلتفرم را قادر میسازد تا قابلیت اطمینان بالا، محافظت از industry-standard و یکپارچگی دادهها و عملکرد قطعی را در مقیاس فراهم کند و در عین حال باعث کاهش ریسک و تسریع نتایج تجاری میشود. این اصول بسیار گسترده هستند که عبارتند از:
- همیشه با نوشتن full stripes، از یک طرح کاملاً ترتیبی پشتیبانی کنید.
- از اندازههای ورودی/خروجی بلوک متغیر استفاده کنید.
- با افزایش تعداد هستههای پردازنده عملکرد را گسترش دهید.
- از معماری scale-up و scale-out برای سازگاری IOPS/TB استفاده کنید.
- قبل از نوشتن دادهها به صورت full stripes در RAID، به طور مداوم بافرهایی را در حافظه غیر فرار مینویسد.
- Cache از حافظه پنهان فلش روی آرایههای هیبریدی به صورت تصادفی خوانده میشود.
- Cache از ذخیره ساز (AFA) all – flash array به صورت تصادفی خوانده میشود.
- اطمینان حاصل کنید که همه نوشتهها از جمله overwriteها، همیشه در فضای آزاد و همجوار اتفاق میافتد.
- از پر کردن حفرهها خودداری کنید و تکه تکه کردن را به صفر برسانید.
- همیشه از روشهای فشردهسازی انطباقی درون خطی برای عملکرد بهتر ذخیرهساز استفاده کنید.
- برای عملکرد بهتر ذخیرهساز، از حذف دادههای تکراری درون خطی استفاده کنید که از موقعیت مکانی استفاده میکند.
- از مکانیسمهای محافظت از داده و یکپارچگی دادهها در برابر خطاهای غافلگیر کننده استفاده کنید که سایر سیستمهای RAID و سیستم کنترل نمیتوانند برطرف کنند.
- با استفاده از QoS (کیفیت سرویس) خودکار، اولویت بندی داخلی ویژگیهای مختلف بارهای کاری و وظایف مدیریت داخلی را ترکیب کنید.
چرا معماری CASL یک طرح متوالی را ارائه و پیاده سازی میکند؟
به چهار دلیل مهم معماری CASL یک طرح کاملا پی در پی را پیادهسازی میکند:
کارایی: هنگامی که رسانه ذخیرهساز نوشتن ترتیبی را سریعتر از نوشتن تصادفی انجام میدهد، سیستم فایل، زمینهای نیاز دارد که نوشتنهای تصادفی را به نوشتنهای ترتیبی تبدیل کند. این مهم برای دیسکهای چرخان اعمال میشود، زیرا نوشتنهای تصادفی برای حرکت دادن به هد دیسک نیاز دارند.
طول عمر: در مورد NAND flash نیز صدق میکند، زیرا قبل از نوشتن یک صفحه متشکل از چندین کیلوبایت، باید کل بلوک چند مگابایتی (بسیاری از صفحات NAND) پاک شود. نوشتن در بلوکهای بزرگ به طور پیدرپی باعث ایجاد بار کاری مناسب NAND میشود که طول عمر رسانه فلش افزایش مییابد.
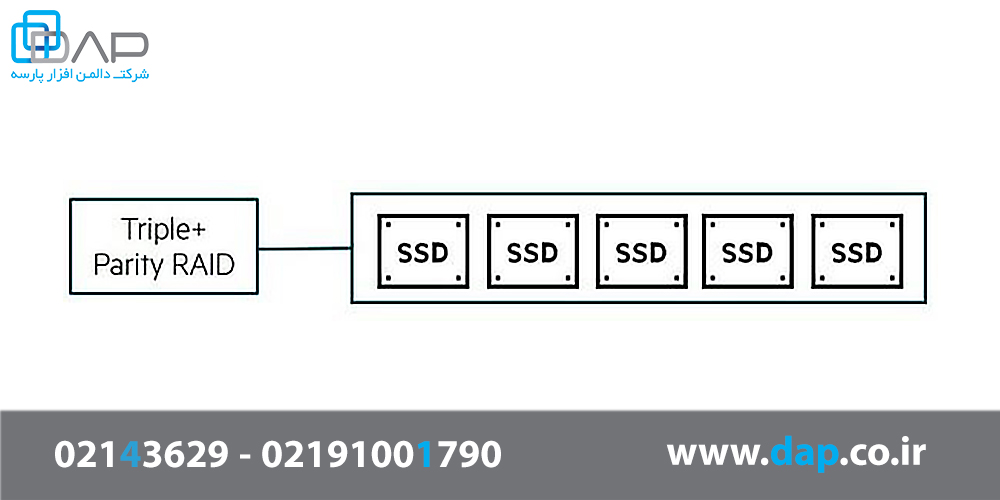
انعطافپذیری: نوشتن متوالی محاسبات RAID، هزینههای سربار را در سیستمها کم میکند، که باعث میشود سازههای RAID با انعطافپذیری شدید مانند Triple Parity + RAID بدون افت عملکرد مورد استفاده قرار گیرند.
پایداری: طرح کاملاً پیدرپی، عملکرد پایدار طولانی مدت را در سطوح مختلف بهرهوری ظرفیت فراهم میکند.
لایه های معماری CASL
معماری CASL متشکل از هفت لایه است که با هم کار میکنند. در ادامه لایه های معماری CASL آورده شده است که عبارتند از :
- لایه RAID
- لایه قطعه (SL)
- لایه LFS
- لایه ذخیره منحصر به فرد بلوک (BUS)
- لایه بلوک شاخص (BI)
- لایه مدیریت حجم (VM)
- لایه SCSI
بررسی لایه RAID در معماری CASL
هدف از طراحی Triple + Parity RAID در استوریج HPE Nimble در مقایسه با سایر روشهای حفاظت RAID این است که انعطاف پذیری بالایی دارد. حتی برای موارد شدید خطاهای خواندن غیرقابل بازیابی وابسته به زمان (URE) که از یک حد تجاوز میکنند هم انعطافپذیر است، در حالی که قابلیت استفاده به طور چشمگیر حفظ میشود: نسبت خام (raw ratio) و عملکرد بالا
بررسی طراحی Triple + Parity RAID
انواع مختلف رسانهها دچار خرابی میشوند برخی از رسانهها ممکن است به طور ناگهانی خراب شوند (به عنوان مثال، موتور یک درایو چرخشی ممکن است به راحتی از کار بیفتد) و انواع دیگر رسانهها ممکن است به تدریج خراب میشوند (به عنوان مثال، با افزایش طول عمر SSDها بیشتر UREها را به نمایش میگذارند). این رفتار هیچ ارتباطی به میزان سایش SSDها و اینکه آیا SLC ، eMLC یا 3D-TLC هستند، ندارد.
هرچه درایوها بزرگتر میشود، احتمال آماری UREهای وابسته به زمان در هنگام بازسازی RAID بیشتر میشود، علاوهبر این، بازسازی RAID ممکن است مدت زیادی طول بکشد (تصور کنید که چند روز یک درایو 200 ترابایتی را دوباره بسازید)، که خطرناشی از وقوع URE را تشدید میکند.
RAID سنتی برای درایوهای بسیار بزرگ مناسب نیست و هنگام مواجهه با خطر ناشی از وقوع URE از یک حد بیشتر نمیتواند در برابر آنها مقاومت کند. به عنوان مثال، RAID 5 میتواند در برابر یک URE مقاومت کند. RAID6 میتواند به طور موازی دو URE را تحمل کند. triple parity RAID نرمال میتواند سه URE را به طور موازی تحمل کند.
Triple + Parity RAID میتواند به تعداد URE ،N را به طور موازی تحمل کند، در واقع N تعداد درایوهای گروه RAID است، حتی اگر همه parity از بین رفته باشد. این بدان معناست که یک سیستم میتواند سه درایو موجود در گروه Triple + Parity RAID را به طور کامل از دست بدهد و در همه درایوهای باقیمانده همزمان URE داشته باشد و این سیستم دچار خرابی اطلاعات نخواهد شد. برای مقابل در یک سیستم RAID5، اگر یک درایو از بین رفته باشد (هیچ parityباقی نماند)، URE صفر میتواند بدون از دست دادن سیستم داده، رخ دهد.
در مقابل، در یک سیستم RAID5، اگر یک درایو از بین برود (هیچ parity باقی نماند)، URE صفر میتواند بدون از دست دادن اطلاعات در سیستم رخ دهد.
سه ویژگی طراحی Triple + Parity RAID
طراحی Triple + Parity RAID دارای ویژگیهای زیر است:
- این برنامه میتواند رسانههای فعلی و آینده را با هم سازگار کند، از جمله رسانههایی که با وقوع غیره منتظره و زیاد UREهای وابسته زمانی روبرو هستند، تا حدی که UREها به طور موازی در همه درایوها اتفاق میافتد.
- این برنامه میتواند درایوهای بسیار بزرگی را در خود جای دهد و زمان بازسازی بسیار طولانی را با اطمینان کامل تحمل کند (به عنوان مثال یک درایو 100 ترابایتی ناکارآمد را بازسازی میکند در حالی که انعطافپذیری بسیار بالایی را برای درایوهای باقی مانده حفظ میکند).
- فضای قابل استفاده با ظرفیت بسیار بالا را فراهم میکند. در واقع فضای استفاده نشده از گروههای بزرگ RAID را میتواند با اطمینان استفاده کند، این بدان معنی است که فضای parity کمتری هدر میرود.
طرح RAID
رسانه (اعم از فلش یا چرخان) به طور خودکار در گروههای RAID سازماندهی میشود که کاملا از کاربر نهایی جدا شدهاند. علاوه بر گروههای RAID، معماری CASL یک الگوریتم Triple + Parity RAID را که از parity توزیع شده استفاده میکند، با یک parity اضافی در هر درایو مرتبط با هر قطعه ( the “+” in Triple+) پیادهسازی میکند.
شکل 2 - لایه RAID
بیشتر بدانید: بلوک بخشی از نوار است. این بلوک مقدار دادهای را که در یک درایو نوشته میشود تعریف میکند و دارای parity اضافی خاص و checksumها است. اندازه بلوک و طرح RAID بین HPE Nimble Storage AFA و سیستمهای هیبریدی متفاوت است.
محافظت از دادههای Extreme
علاوه بر Triple Parity، که به صورت افقی در کل یک نوار محاسبه میشود، تعادل هر درایو را هم محاسبه میکند. این نوع تعادل که به آن Triple + Parity RAID نیز گفته میشود، با استفاده از مقدار قابل توجه داده و متا دادهای که در هر درایو نوشته و به صورت محلی ذخیره شده، محاسبه میشود. از Parity هر درایو میتوان برای بازیابی از URE استفاده کرد، حتی اگر هیچ افزونگی در این نوار باقی نماند (به عنوان مثال، اگر سه درایو خراب شود و URE در هنگام بازسازی ایجاد شود.) Parity در هر درایو اجرا شده است.
Parity موجود در هر درایو در هر دو سیستمعامل HPE Nimble Storage All Flash (AF) و Hybrid Flash (HF) پیادهسازی شده است. این امر امکان بازیابی از چهار خطای ECC متوالی در SSDها یا دو خطای خواندن سکتور در HDDها با فرمت 512B یا یک خطای خواندن سکتور در HDDها با فرمت 4KB را فراهم میکند. علاوهبر این، ریکاوری هیچ ارتباطی با وضعیت درایوهای باقی مانده ندارد. این بدان معنی است که یک گروه RAID Triple + Parity میتواند سه درایو را از دست بدهد و همچنان از خطاهای خواندن سکتور محافظت کند. در واقع این کار با RAID استاندارد غیر ممکن است.
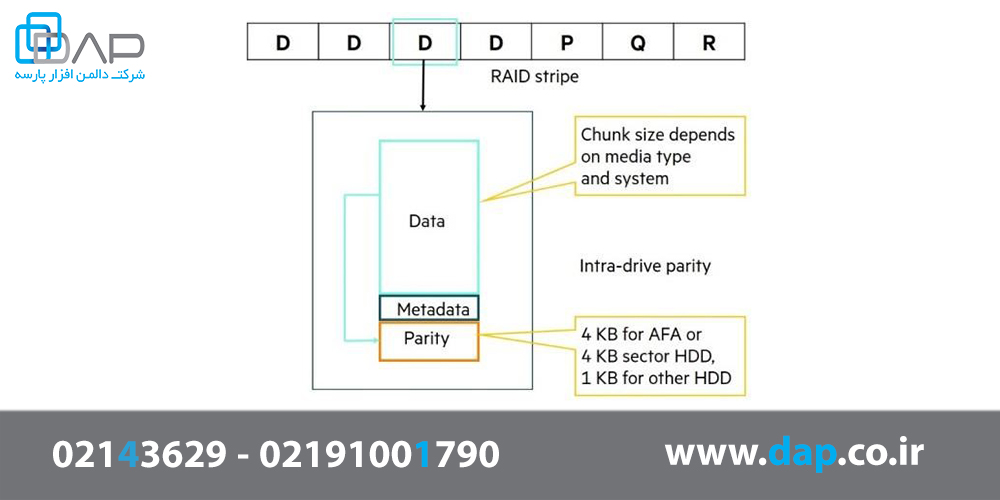
شکل 3 - درون درایو در هر قطعه parity
توسط رسانه به طور نامتقارن انجام میشود. به عنوان مثال، پاک کردن و نوشتن سلولهای حافظه فلش زمان بسیار بیشتری نسبت به خواندن آن نیاز دارد. فلش همچنین دارای چرخه عمر نوشتاری محدودی است، بنابراین نحوه نوشتن سیستم ذخیرهساز برای آن بسیار مهم میشود.
CASL همیشه از یک طرح کاملا پیدرپی برای نوشتن دادهها به صورت خطی استفاده میکند، بدون اینکه باعث تغییر نوشتن، تاخیر در خواندن شود.(حتی در ظرفیت بسیار بالای نرخهای بهره وری). این روش با سایر پیادهسازیهای LFS متفاوت است.
اندازه نوار یا اندازه سگمنت با ضرب تعداد درایوهای داده در اندازه سگمنت تعیین میشود و این اندازه بین AFA و سیستم عاملهای ترکیبی متفاوت است.
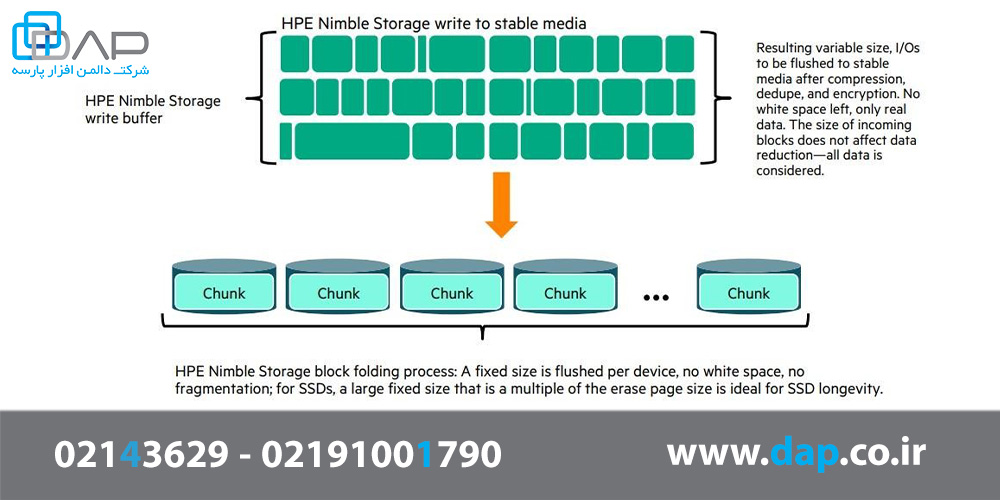
شکل 4 - نحوه نوشتن استوریج HPE Nimble در رسانههای پایدار در بلوکها
مقایسه Triple + Parity RAID با انواع RAID سنتی
تمام سیستمهای محافظت از داده دارای زمان متوسط برای از دست دادن دادهها (MTTDL) هستند. این میانگین زمان از دست دادن داده است که با عملکردهای سیستم ذخیرهساز (Parity، پشتیبانگیری و بازسازی) قابل بازیابی نیست. هدف یک سیستم ذخیرهساز با یکپارچگی وانعطافپذیری داده قوی این است که زمان از دست رفتن دادهها را هم در نظر میگیرد. بنابراین در آینده حتی در شرایط نامساعد هیچ دلیلی برای نگرانی در مورد آن وجود ندارد.
انتشار بالای URE به طرز چشمگیری MTTDL را کاهش میدهد. جدول 1 مقایسه MTTDL را با فرضیات مختلف نشان میدهد. این کار با استفاده از ریاضی استاندارد MTTDL انجام شده است.
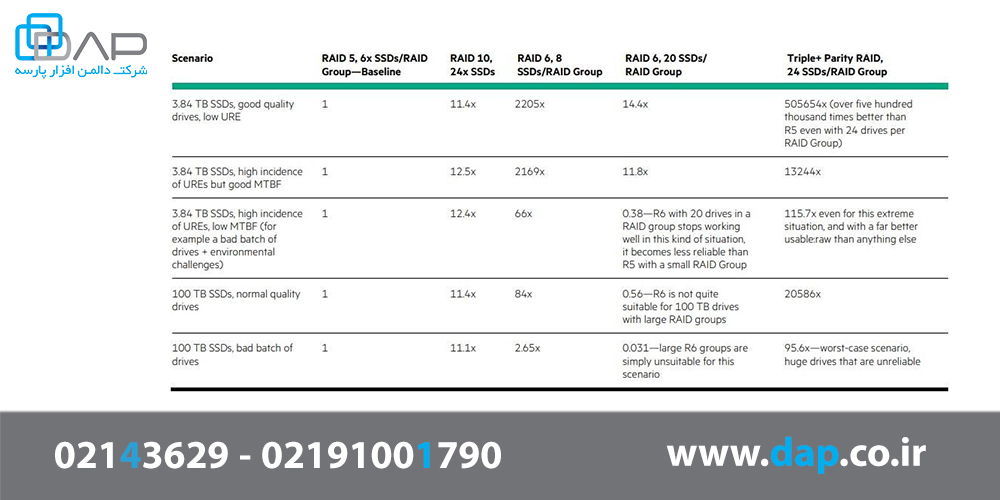
جدول 1 - زمان متوسط برای از دست دادن دادهها Triple+ Parity RAID در مقایسه با انواع RAID سنتی و اندازه گروه
توجه داشته باشید که Triple + Parity RAID در این مثال ها دارای اندازه گروه RAID بسیار بزرگتر از بقیه (24 درایو) است.در ریاضیات RAID، هر چه تعداد درایوها در گروههای RAID بیشتر باشد، قابلیت اطمینان آن پایین است. Triple+ Parity RAID به قابلیت اطمینان فوقالعاده بالایی دست مییابد در حالی که امکان استفاده از اندازههای بزرگ گروه RAID را فراهم میکند که این امر به دستیابی بسیار زیاد دادههای خام از دست رفته کمک میکند.
حتی پیادهسازی بسیار محافظه کارانه RAID6 که فقط 8 دیسک در هر گروه RAID دارد، دسترسی ضعیفی خواهد داشت: از آنجا که میزان Parity دادههای خام برای 24 دیسک دو برابر در مقابل Triple + Parity RAID است، با این وجود محافظت ارائه شده برای Triple + Parity RAID بسیار کمتر است. درمیان انواع RAID طرح Triple + Parity RAID انعطافپذیرتر هستند.
***توجه: برای محاسبات MTTDL در جدول، از متغیرهای زیر استفاده شده است:
- 150 MB/s rebuild speed
- Normal quality drives: 1.2M hours MTBF, 1 in 1017 URE
- Bad batch of drives: 36.5K hours MTBF, 1 in 106 URE
Checksumهای چند مرحلهای آبشاری
هدف طراحی checksum در استوریج HPE Nimble ایجاد فضای ذخیرهسازی ایمن توسط انواع checksumهای سنتی با ایجاد روشی برای شناسایی و تصحیح خطاهای آرایه داخلی است که غیرقابل شناسایی هستند.
مرکز طراحی برای checksumهای HPE Nimble Storage
یک تصور غلط رایج در مورد RAID این است که یکپارچگی دادهها را تضمین میکند. RAID به خودی خود، هر چقدر هم که قوی باشد، نمیتواند از انواع مختلف خرابی دادهها جلوگیری کند.
checksumهای سنتی و استاندارد صنعتی (industry-standard) همانطور که در بسیاری از دستگاههای ذخیرهسازی یافت میشود، نمیتواند از خطاهایی مانند نوشتن از دست رفته، خواندن اشتباه و نوشتن نا به جا جلوگیری کند. صنعت ذخیرهسازی این نوع خطاها را خطاهای silent مینامد. تا زمانی که سیستم ذخیرهساز مکانیسمهای لازم برای شناسایی و بازیابی را فراهم نکند، این خطاها همیشه منجر به خرابی دادهها میشوند و ردیابی آنها بسیار دشوار است.
در نتیجه، بسیاری از کاربران از وجود چنین خطاهایی آگاهی ندارند، فقط به این دلیل که اکثر سیستمهای ذخیرهساز به راحتی مکانیسمهای تشخیص و اصلاح لازم را برای این خطاها ارائه نمیدهند. علاوهبر این، سیستمهای ذخیرهساز مدرن، متا داده زیادی تولید میکنند. بنابراین هرگونه خرابی متا داده ممکن است عواقب فاجعه باری برای اکثر دادهها به همراه داشته باشد.
با حذف دادههای تکراری، snapshotها، cloneها و کپیها، هرگونه خرابی روی بالاترین دادههایی که بیشترین ارجاع به آنها وجود دارد، در واقع به این معنی است که چندین بلوک منطقی اکنون خراب شدهاند.
توجه داشته باشید که بدترین انحراف، خطاهای silent است که منجر به خواندن دادههای اشتباه میشود.
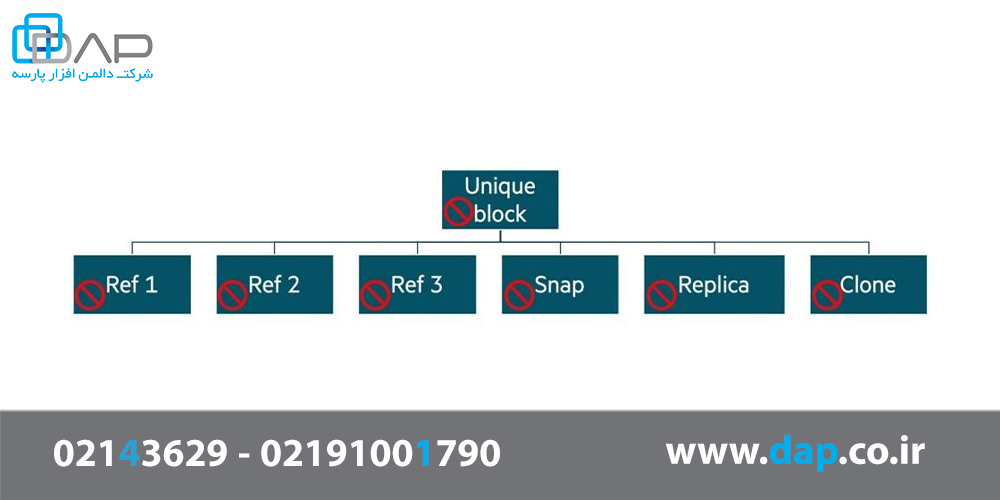
شکل5 - اثر دومینوی فاجعه بار خطای Silent در یک بلوک
سناریوی نشان داده شده در شکل 5 را در نظر بگیرید. تصور کنید که یک خطای خواندن نادرست بر بلوک منحصر به فرد تأثیر میگذارد، خطایی که توسط checksumهای استاندارد قابل تشخیص نیست. تمام بلوکهای منطقی متکی به این بلوک منحصر به فرد خراب میشوند، بدون اینکه کاربران از خطا اطلاع داشته باشند. همه موارد تکراری، snapshotها،clone ها و remote replicaها، که بر چندین LUN (Logical Unit Number) در سیستم تأثیر میگذارد از همان بلوک منحصر به فرد استفاده میکنند. به طور بالقوه صدها منبع مجازی از این بلوک، هنگام خواندن، داده اشتباه را بر میگردانند. این نوع انحراف منطقی اثر دومینو، اطمینان از صحت دادههای داخلی را بیش از گذشته مهم میکند. در سیستمهای ذخیرهسازی قدیمی با LUNها که در یک گروه RAID واحد قرار میگیرند، هرگونه انحراف، محدود به LUN و برخی snapshotها خواهد بود. در سیستمهای امروزی چنین انحرافی گسترده خواهد بود. به همین دلیل ذخیره ساز HP Nimble یک سیستم جامع برای محافظت کامل در برابر چنین خطاهایی ساخته است.
سه دسته اصلی خطا
سه دسته اصلی خطا وجود دارد که شناسایی این خطاها دشوار است:
1- Lost write: نوشتن در ابتدا کامل به نظر میرسد و کل فرآیند RAID را به درستی طی میکند. اما ممکن است رسانه ذخیرهسازی دادههای نوشته شده را ثبت نکند. هنگام خواندن این داده، دادههای قدیمی موجود در آن مکان به جای آن خوانده میشوند. ممکن است از نظر فنی دادهها خراب نباشد، اما از نظر زمانی اشتباه باشد. از آنجا که این دادهها خراب به نظر نمیرسند، سیستمهای کنترل سنتی، خطا را تشخیص نمیدهند.
2-Misdirected write: نوشتن، کل فرآیند RAID را به درستی تکمیل و طی میکند. همچنین کاملا به محیط ذخیرهساز متعهد است ولی در مکان اشتباه نوشتن صورت گرفته است. هنگام تلاش برای خواندن دادهها، دادههای قدیمی (قبلا صحیح) به جای آن از مکان صحیح خوانده میشوند. این امر توسط checksumهای سنتی تشخیص داده نمیشود زیرا داده خراب نیست، بلکه نسخه قدیمی دادهها خوانده میشود.
3-Misdirected read: دادهها از مکان اشتباه خوانده میشوند. دادههای خوانده شده صحیح اما دادههای اشتباهی هستند. checksumها دوباره این نوع مشکل را تشخیص نمیدهند.
تحقیقات نشان میدهد که این نوع خطاها معمولا به دلیل اشکال میان افزار در درایوها رخ میدهند. تشخیص این خطاها بسیار سخت است (و در واقع با بسیاری از آرایهها قابل تشخیص نیست). در نتیجه ممکن است خطاها برطرف نشوند تا زمانی که شخصی با ابزار تشخیص خطاها به تولیدکنندگان درایو هشدار دهد. خوشبختانه محاسبات کنترل HPE Nimble Storage (با استفاده از معماری CASL) به قدری قوی هستند که حتی درایوهای فوقالعاده مشکلساز نیز منجر به انحراف اطلاعات نمیشوند.
Checksumهای چند مرحلهای آبشاری HPE Nimble Storage چگونه کار میکنند؟
علاوهبر ذخیره دادههای checksum، به هر شی ذخیره شده یک شناسه منحصر به فرد نیز اختصاص داده میشود.
شناسه منحصر به فرد یک شماره واحد نیست. این شناسه شامل چندین داده از جمله آدرس بلوک همراه با یک شماره سریال منحصر به فرد تکرار نشدنی است.
SBN (sequential block number) برای همه دادهها متفاوت خواهد بود حتی اگر دادههای مشابه بخواهند رونویسی شوند (به عنوان مثال تلاش برای بهروز رسانی یک بلوک با دادههای مشابه). این امر با استفاده از شاخصهای مختلف، نقشههای CASL و ردیابی SBNها، checksumها و محل بلوک بر روی دیسک حاصل میشود، که این کار تشخیص و اصلاح خطای silent را آسانتر میکند و قوانین دقیق دستور نوشتن را حفظ میکنند.
سیستمهای سنتی کنترلی، بخش شناسه خود را حذف میکنند (یا یک مجموعه ساده و کوچک از اعداد غیر منحصر به فرد دارند) و دقیقا این شناسه منحصر به فرد است که امکان شناسایی کامل خطاها مانند نوشتنهای از دست رفته(نوشتن های گم شده) را فراهم میکند.
هنگام خواندن، هر دو بخش كنترل و شناسه منحصر به فرد با آنچه در رسانه ذخیره شده است، مقایسه میشوند. اگر هر دو با آنچه هست، مطابقت نداشته باشند انتظار میرود، دادههای خراب به طور شفاف از Triple + Parity RAID بازسازی شود:
1. در صورت خراب بودن دادهها، checksum آنها را برطرف میکند.
2. اگر دادهها از مکان اشتباه خوانده شوند، دارای شناسه منحصر به فرد اشتباه هستند – دادههای صحیح از Triple + Parity RAID بازسازی میشوند.
3. اگر نوشتهها از بین بروند، دادههای قدیمی دارای شناسه منحصر به فرد اشتباه هستند – دادههای صحیح از Triple + Parity RAID بازسازی میشوند.
جمعبندی checksum strong در چندین سطح انجام میشود، نه فقط در هر بلوک. که این کار منجر به یک آبشار از checksumها در چندین مرحله از مسیر ورودی/خروجی میشود.
برای علامتگذاری قطعهای از دادهها به عنوان داده درست و صحیح، باید تمام مراحل checksum باید درست و صحیح باشد:
- همانطور که دادهها به حافظه و NVDIMM وارد میشوند
- قبل و بعد از کاهش دادهها
- در هر بلوک ذخیره شده
- به ازای هر قطعه
- در هر snapshot
- برای دادههای تکراری
بسیاری از سیستمها بر اساس هر بلوک ذخیره شده، checksumها را پیش میبرند، این بدان معنی است که ممکن است خرابی منطقی دادههای تکثیر شده شناسایی نشود. در همه مراحل با استفاده از CASL، صحت دادهها در تمام مراحل چک میشود.
ویژگی های عملکرد checksumهای چند مرحله ای آبشاری
این محافظت گسترده، مرحلهای اساسی از سیستم است و نمیتواند غیرفعال شود (دقیقا مانند یک نوع +RAID: Triple).
یک سوال متداول این است که آیا این سطح شدید حفاظتی عملکرد را پایین میآورد؟
از آنجا که CASL تمام دادهها را به طور متوالی مینویسد، ذخیره این اطلاعات اضافی از نقطه نظر ورودی/خروجی کار دشواری نیست. این امر در مقایسه با checksumهایی که از خطاهای احتمالی (موذی) محافظت نمیکنند، به پردازنده اضافی نیاز دارد اما این کار ارزشمند است، زیرا بازده یکپارچگی دادهها بسیار زیاد است. اطلاعات checksum فضای اضافی بیشتری را اشغال میکند و این مقدار در اندازهگیری در نظر گرفته میشود.
ابزار اندازهگیری HPE هنگام تخمین عملکرد و ظرفیت، شامل سیستم کاملی است که تمام هزینههای سربار، متا دادهها، checksumming و Triple + Parity RAID را در بر میگیرد.
پاکسازی دیسک
پاکسازی دیسک روشی است که به موجب آن یک آرایه ذخیرهساز، دادههای موجود را به تنهایی میخواند، اسکن خطاها را انجام میدهد و خطاهای خواندن را برطرف میکند. سیستمهای HPE Nimble Storage پاکسازی مداوم انجام میدهند. توجه به این نکته مهم است که پاکسازی دیسک ممکن است مفید باشد، اما جایگزین RAID strong و checksum نمیشود. این کار از نظر ماهیت اولویت پایینی دارد و نمیتواند خطاهایی که در زمان واقعی باعث اختلال در سیستم میشوند را فراتر از آنچه که checksumها و RAID میتوانند رفع کنند، برطرف کند. (ورودی و خروجی کاربر همیشه در تمام آرایههای دیسک از اولویت پاکسازی دیسک بالاتر است).
مترجم: محبوبه فغانی نرم




)





















